
The big data movement is creating opportunities for the chemical process industries to improve their operations. Challenges, however, lie ahead.
The big data movement is gaining momentum, with companies increasingly receptive to engaging in big data projects. Their expectations are that, with massive data and distributed computing, they will be able to answer all of their questions — from questions related to plant operations to those on market demand. With answers in hand, companies hope to pave new and innovative paths toward process improvements and economic growth.
An article in Wired magazine, “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete” (1), describes a new era in which abundant data and mathematics will replace theory. Massive data is making the hypothesize-model-test approach to science obsolete, the article states. In the past, scientists had to rely on sample testing and statistical analysis to understand a process. Today, computer scientists have access to the entire population and therefore do not need statistical tools or theoretical models. Why is theory needed if the entire “real thing” is now within reach?
Although big data is at the center of many success stories, unexpected failures can occur when a blind trust is placed in the sheer amount of data available — highlighting the importance of theory and fundamental understanding.
A classic example of such failures is actually quite dated. In 1936, renowned magazine Literary Digest conducted an extensive survey before the presidential election between Franklin D. Roosevelt and Alfred Landon, who was then governor of Kansas. The magazine sent out 10 million postcards — considered a massive amount of data at that time — to gain insight into the voting tendencies of the populace. The Digest collected data from 2.4 million voters, and after triple-checking and verifiying the data, forecast a Landon victory over Roosevelt by a margin of 57% to 43%. The final result, however, was a landslide victory by Roosevelt of 61% versus Landon’s 37% (the remaining votes were for a third candidate). Based on a much smaller sample of approximately 3,000 interviews, George Gallup correctly predicted a clear victory for Roosevelt.
Literary Digest learned the hard way that, when it comes to data, size is not the only thing that matters. Statistical theory shows that sample size affects sample error, and the error was indeed much lower in the Digest poll. But sample bias must also be considered — and this is especially critical in election polls. (The Digest sample was taken from lists of automobile registrations and telephone directories, creating a strong selection bias toward middle- and upper-class voters.)
Another example that demonstrates the danger of putting excessive confidence in the analysis of big data sets regards the mathematical models for predicting loan defaults developed by Lehman Brothers. Based on a very large database of historical data on past defaults, Lehman Brothers developed, and tested for several years, models for forecasting the probability of companies defaulting on their loans. Yet those models built over such an extensive database were not able to predict the largest bankruptcy in history — Lehman Brothers’ own.
These cases illustrate two common flaws that undermine big data analysis:
- the sample, no matter how big, may not accurately reflect the actual target population or process
- the population/process evolves in time (i.e., it is nonstationary) and data collected over the years may not accurately reflect the current situation to which analytics are applied.
These two cases and other well-known blunders show that domain knowledge is, of course, needed to handle real problems even when massive data are available. Industrial big data can benefit from past experiences, but challenges lie ahead.
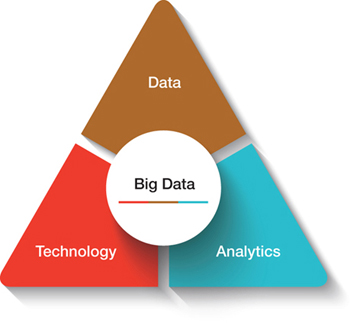
▲Figure 1. The big data movement stems from the availability of data, high-power computer technology, and analytics to handle data characterized by the four Vs — volume, variety, veracity, and velocity.
Like any new, promising field, big data must be viewed in terms of its capabilities as well as its limitations. Some of these limitations are merely challenges that can be addressed — enabling companies to make the most out of new opportunities created by data, technology, and analytics (Figure 1).
This article outlines ten critical challenges regarding big data in industrial contexts that need to be addressed, and suggests some emerging research paths related to them. The challenges are discussed in terms of the four Vs that define the context of big data: volume, variety, veracity, and velocity.

Big data is, first of all, about handling massive amounts of data. However, in industrial processes, the first thing to realize is that not all data are created equal. Several challenges arise from this point.
Meaningful data. Most industrial big data projects rely on happenstance data, i.e., data passively collected from processes operating under normal operating conditions most of the time. Thus, a large amount of data is indeed available, but those data span a relatively narrow range of operating conditions encountered during regular production situations.
Data sets collected under those circumstances may be suitable for process monitoring and fault detection activities (2), which rely on a good description of the normal operating conditions (NOC) as a reference to detect any assignable or significant deviation from such behavior. However, their value is limited for predictive activities, and even more so for control and optimization tasks. Prediction can only be carried out under the same conditions found in the data used to construct the models. As a corollary, only when all the NOC correlations linking the input variables are respected can the model be used for prediction.
For process control and optimization activities, the process description must capture the actual influence of each manipulated input variable on the process outputs. Its construction requires experimentation — i.e., the active collection of process data via a design of experiments (DOE) program for process optimization or via system identification (SI)...
Would you like to access the complete CEP Article?
No problem. You just have to complete the following steps.
You have completed 0 of 2 steps.
-
Log in
You must be logged in to view this content. Log in now.
-
AIChE Membership
You must be an AIChE member to view this article. Join now.
Copyright Permissions
Would you like to reuse content from CEP Magazine? It’s easy to request permission to reuse content. Simply click here to connect instantly to licensing services, where you can choose from a list of options regarding how you would like to reuse the desired content and complete the transaction.