
-

-
Topics:
by Moritz von Stosch, PhD
Imagine you want to make beer, and not just any beer, but great beer. You have all the ingredients, all the equipment and you already made your first attempt with a simple recipe. Now, how do you start to improve the taste?
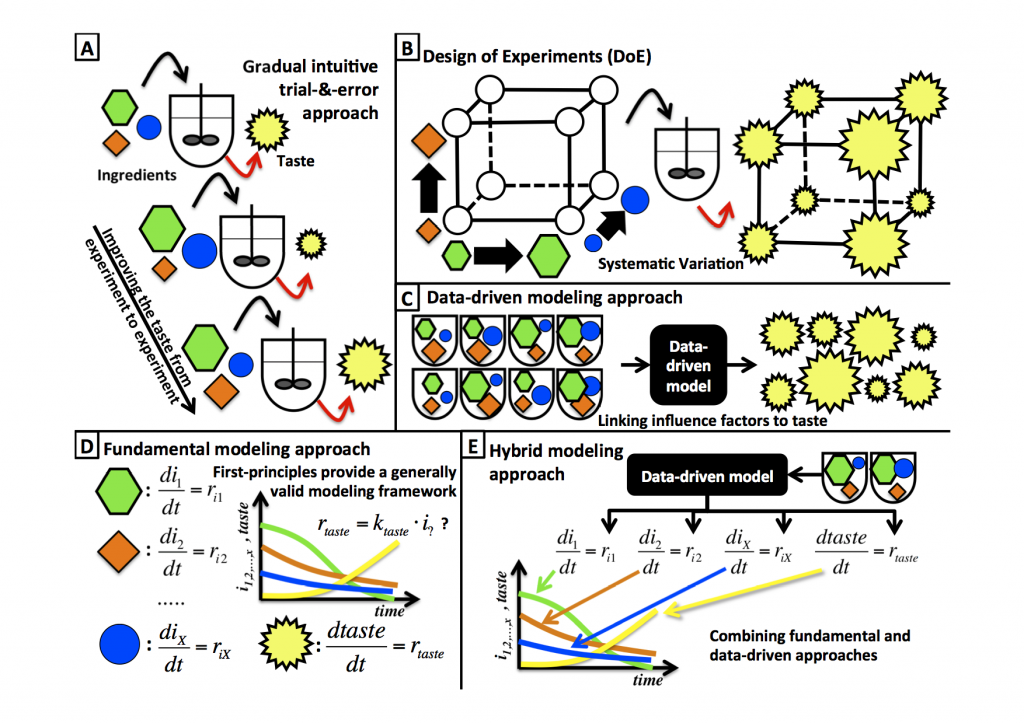
One simple way to is to gradually note changes in taste as you vary the amount of ingredients, adjust the fermentation time, or alter the fermentation temperature (Figure 1a, below). You could even do this more systematic by applying a statistical design of experiments, making sure that you capture all possible influence factors (Figure 1b). The next step would probably be to quantify the taste more objectively, using some analytic device rather than tasting and rating the beer yourself. Once you are at this level, i.e., you already have a lot of data, you might as well decide to use a data-driven modeling tool, which links the different influence factors (such as ingredients, fermentation time or temperature) to the analytic quantified taste of beer (Figure 1c).
Most likely this data-driven model would tell you how the optimal factors might make your beer taste good. Simple, systematic, and objective oriented, this seems to be a good approach, and yet you hardly used your chemical engineering education, even though brewing beer is the kind of batch process you learned so much about in school. So how would you solve this problem using your education?
Putting chemical engineering skills to work
That's right, material balances! Just do the balance for ingredient 1, ingredient 2, ingredient x and the balance of the taste. Done? Does it look like in Figure 1d? But what order do the reaction rates belong to? Most reactions are of the first order so you might stick with that, even though it is a bioprocess? You could also do some fermentations and try to figure out what the most suitable expression for the reaction rates is, but that will probably take significant time and effort. Nevertheless, with the help of the model you will finally get a good--maybe even better tasting--beer.
Which option do you think requires the least effort, and which one will identify the best taste? Depending on the circumstances, either could be successful, and either one could turn out to be easier. But why use only one or the other option and not combine both, with hybrid modeling?
What is hybrid modeling?
The first modeling approach is data-driven, the second approach is fundamental. The combination of the two is typically referred to as hybrid modeling, more specifically hybrid semi-parametric modeling.
This method allows you to integrate all available knowledge into one approach, while reducing effort and maintaining accuracy. In the above case, for example, you can derive the material balances, but instead of trying to derive an expression for the kinetic rates, a data-driven model would be used for their representation (Figure 1e). Thus, it's easier to derive this model compared to a fundamental model. In addition, fewer experiments are usually required to derive the data-driven model that is a part of the hybrid model, compared to a standalone data-driven model. The reason for this is because the incorporated fundamental knowledge structures the interactions of the variables, whereas they must be tested experimentally for strictly data-driven models. For example, the impact of the fermentation time is implicitly captured in the hybrid model, whereas the impact of the standalone data-driven model would have to be tested experimentally. In general, hybrid models offer a higher benefit/cost ratio for solving complex models, compared to models solely base on one source of knowledge.
What are hybrid models best suited for?
Each modeling approach, whether hybrid, fundamental, or data-driven, is suited for certain conditions. Fundamental models allow explaining the behavior of a system in a broad range. Data-driven approaches can be applied when nothing at all is known about the functioning of the system. Every time different sources of knowledge are available, it is efficient to use hybrid models, especially when the model development is rather objective-driven (e.g., a model for optimization). As such, hybrid modeling is very attractive for applied research.
Imagine you already derived a fundamental model, but for some reason the estimation error values are great for some of the experiments. In this case you could use a data-driven model in parallel to the fundamental model, in order to identify whether the estimation error can be explained by a function of variable combinations, as is shown in Figure 2. This can help to understand what part of the model needs to be refined.
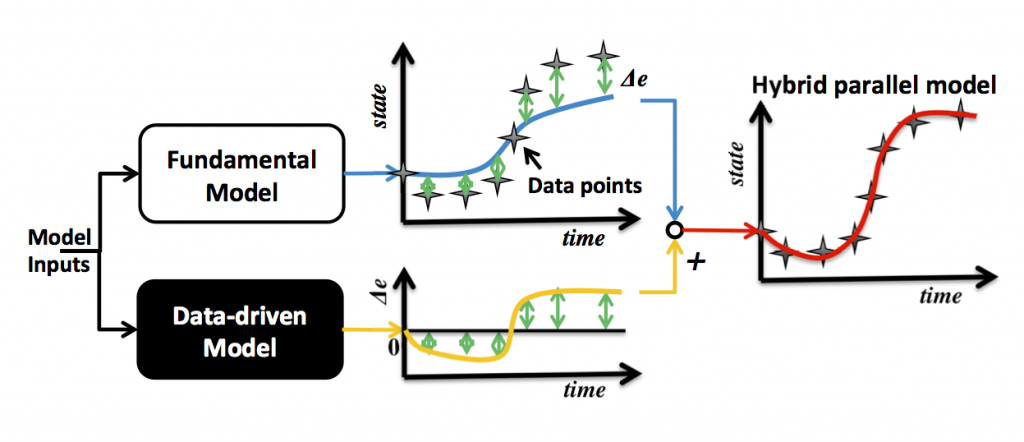
The other possibility is to use a data-driven model to represent the variables in the fundamental model for which it is difficult to derive mathematical expressions, such as for the reaction rates in the case above. This approach, referred to as serial hybrid model, allows describing and understanding a system, even though the underlying phenomena are unidentified at the outset.
Applying hybrid models to your projects
Hybrid models can provide accurate predictions at an acceptable cost. They can successfully be applied to advanced process monitoring, optimization and control (check out these for more information: Article 1, Article 2, Article 3). The above outlined features of hybrid models have the potential to save resources, reduce timelines, and improve manufacturing. If hybrid modeling could work for you, consider also checking out this article (in addition to the articles listed above) and this course as one starting point.
Dr. Moritz von Stosch is a member of the faculty in the Department of Chemistry, Faculty of Sciences and Technology, at Portugal's Universidade Nova de Lisboa.