2022 Annual Meeting
(684a) Towards Catalysis Informatics: How the Particularities of Catalytic Data Impact Machine Learning
Authors
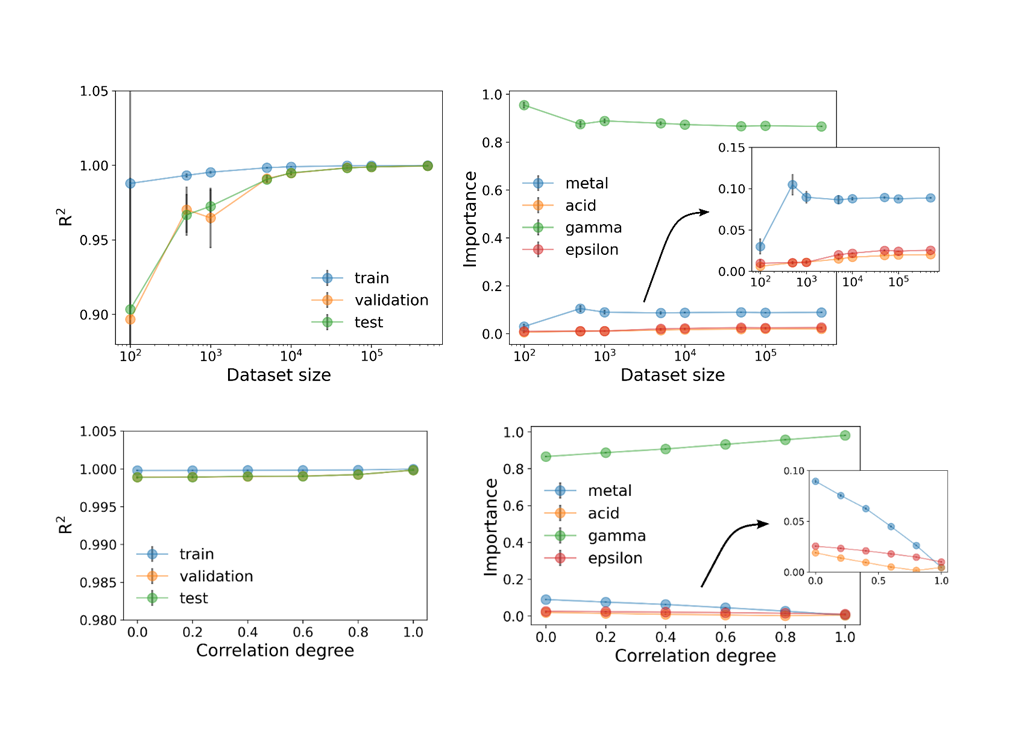
To investigate the individual impact of key data characteristics, datasets were constructed via an interpretable kinetic model. It features only four parameters: the metal and acid sites concentrations and two lumped kinetic parameters (epsilon and gamma) that are catalyst structure-dependent. Random forest regressor was selected as ML method, because of the features importance quantification. All variables were normalized using the standard score and the data was randomly split into 80% training, 10% validation and 10% testing datasets during 10-fold cross validation.
Data size was researched first, as experimental data in catalysis is rather small. The model predictivity deteriorates significantly below 103 datapoints (see figure, top). Similarly, the feature importances of are affected. Further reducing the data size, epsilon and acid importance become indistinguishable. Highly correlated features are also typical of catalysis. For instance, in metal-zeolite catalysts, metal loading influences the concentration of metal sites, but also that of acid sites because metals can exchange protons with zeolites. While model performance is barely affected, feature importance depends on the degree of correlation between features (see figure, bottom). Particularly, if metal and acid sites concentrations are strongly correlated, both features become irrelevant to the model, while being physically critical to achieve optimal catalysts.
Typical catalytic data does significantly deteriorate the results of ML models, advising for a robust model selection. Further investigations will determine focus on correlation-types common in catalysis and experimental error.