2020 Virtual AIChE Annual Meeting
(537d) An All-in-One Approach for Training Deep Learning-Based Control Laws
Author
Model predictive control (MPC) provides a general framework for controlling nonlinear systems. However, the high online computational latency limits the scope of its application for systems with fast dynamics. One way to enable the real-time application of MPC is to approximate the implicit MPC control law with a neural network [1,2,3]. The hypothesis of this approach is that a deep learning neural network can sufficiently approximate the nonlinear behavior of MPC, but at a negligible online computational cost that is significantly better than that of a full-fledged MPC. For linear systems with quadratic cost function, a neural network with rectified linear units as activation functions can exactly represent piecewise affine optimal control laws [4].
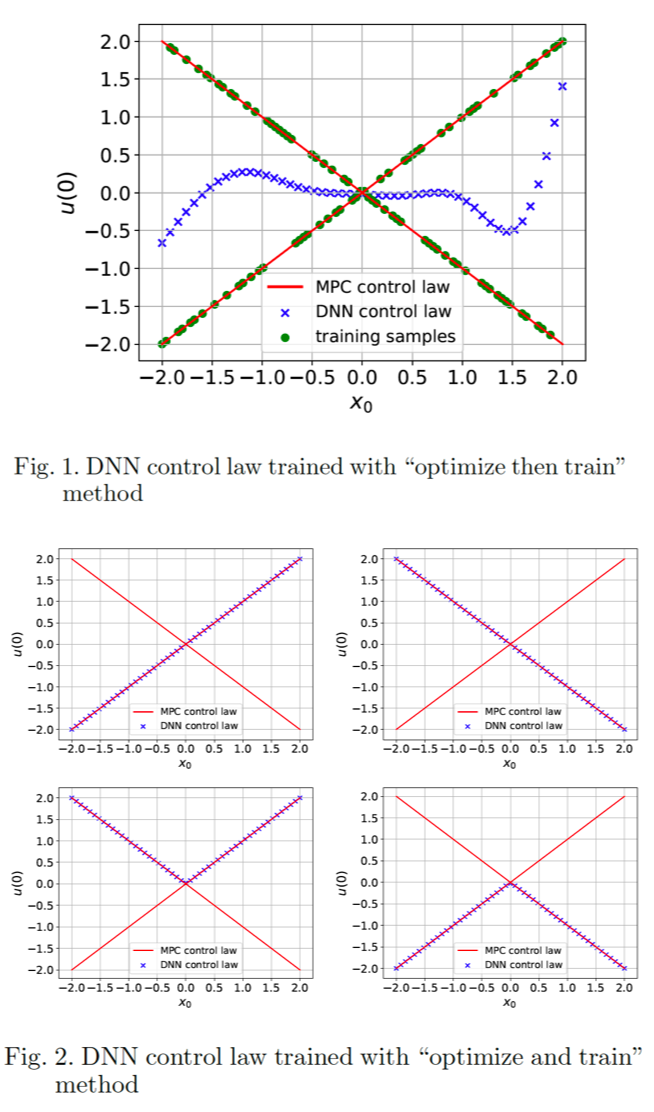
An essential aspect of the above-mentioned approaches is the training of large dimensional neural networks. Many researchers follow the "optimize then train" protocol. The idea in these algorithms is to simulate the optimal controller, generate corresponding state and optimal control action data pairs and then use these data to train a neural network via supervised learning to approximate the original optimal controller. Unfortunately, this conventional "optimize then train" protocol is not guaranteed to work on nonlinear systems. For nonlinear systems, it is possible that multiple optimal control actions exit for the same initial state. In this case, the MPC control law is a set-valued function. The non-uniqueness of the state-action data pairs makes it impossible to learn the underlying MPC control law through this two-step approach, as illustrated in Figure 1. Even if the uniqueness of optimal control actions is guaranteed, the optimal control problem might have multiple local optimal control actions, which are typically identified using local solvers. Moreover, for general nonlinear systems, no neural network structure with finite neurons can guarantee an exact representation of the MPC control laws. The training error of the neural network can lead to sub-optimal control actions and state constraint violations. The resulting errors could potentially accumulate over time and eventually making the neural network deviate significantly from the optimal control.
We propose a new "optimize and train" method that combines the steps of data generation and neural network training into one single large-scale stochastic optimization problem. This approach directly optimizes the closed loop performance of the DNN controller over a number of possible initial states. Directly optimizing the control law instead of control actions avoids the difficulty caused by the nonuniqueness of optimal control actions, as shown in Figure 2. Moreover, all constraints are guaranteed to be satisfied for all initial state scenarios considered in the optimization, while this guarantee does not hold for the conventional "optimize then train" method. We also propose methods to ensure constraints satisfaction for all possible initial states. The critical challenge is the solution a large-scale nonlinear stochastic optimization problem. However, tremendous progress has been made recently in the field of stochastic optimization that allows us to design and implement efficient local and global algorithms [5,6]. Besides directly using stochastic optimization solvers, we also proposed a recurrent neural network formulation for nonlinear systems with input constraints and soft state constraints. This approach can take advantage of existing packages (e.g., TensorFlow) in the machine learning community and can potentially tackle extreme-scale problems efficiently with GPUs. The benefits of our all-in-one approach over the conventional ``optimize then train" protocol is illustrated through numerical results.
References:
[1] Parisini, T., & Zoppoli, R. (1995). A receding-horizon regulator for nonlinear systems and a neural approximation. Automatica, 31(10), 1443-1451.
[2] CsekÅ, L. H., Kvasnica, M., & Lantos, B. (2015). Explicit MPC-based RBF neural network controller design with discrete-time actual Kalman filter for semiactive suspension. IEEE Transactions on Control Systems Technology, 23(5), 1736-1753.
[3] Chen, Y., Shi, Y., & Zhang, B. (2018). Optimal control via neural networks: A convex approach. arXiv preprint arXiv:1805.11835.
[4]Karg, B., & Lucia, S. (2018). Efficient representation and approximation of model predictive control laws via deep learning. arXiv preprint arXiv:1806.10644.
[5] Cao, Y., Zavala, V. M., & DâAmato, F. (2018). Using stochastic programming and statistical extrapolation to mitigate long-term extreme loads in wind turbines. Applied energy, 230, 1230-1241.
[6] Cao, Y., & Zavala, V. M. (2019). A scalable global optimization algorithm for stochastic nonlinear programs. Journal of Global Optimization, 75(2), 393-416.