(156d) A Deep-Learning Model of a Crude Distillation Unit
AIChE Annual Meeting
2022
2022 Annual Meeting
Topical Conference: Next-Gen Manufacturing
Applied Artificial Intelligence, Big Data, and Data Analytics Methods for Next-Gen Manufacturing Efficiency II
Monday, November 14, 2022 - 1:48pm to 2:06pm
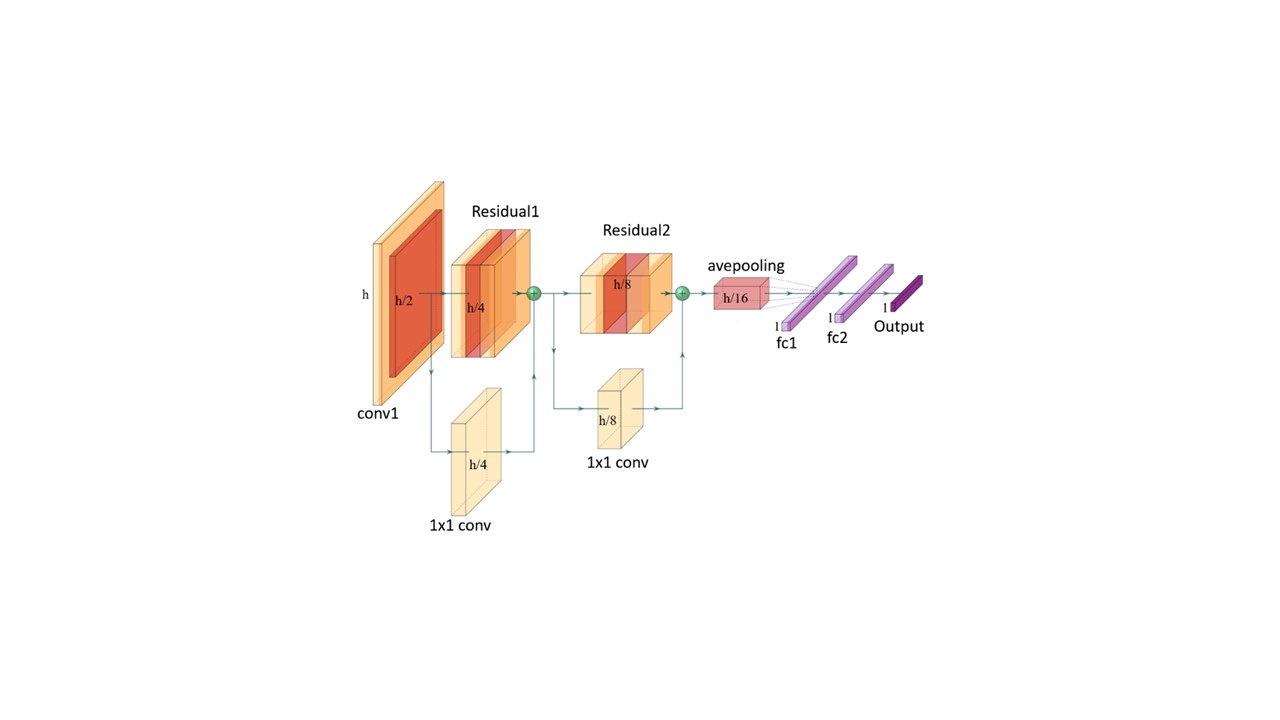
This work introduces a new deep neural network structure for modeling the primary processing unit in the refinery, including the pre-flash tower, atmospheric tower, and vacuum tower. The model predicts properties of the products. Inspired by the work presented by Song in 2020[8], the model structure in this work contains two parts. The former part is the “figure generation†part, which converts the input variables into a two-dimensional “figure.†The latter part is the convvolutional neural network (CNN), which processes these “figures†and generates predictions. Since the size of the input for the CNN is preferably a square, the number of the input variables will not form a proper square exactly. There are two ways to generate the suitable input “figures†for CNN. One is to increase the dimensionality that maps the input into a larger square-sized “figure.†Another way is to map the input into a smaller square-sized “figure†through some dimensionality reduction methods. Both ways have been evaluated by using SOM (self-organizing-map) and PCA (Principal Component Analysis), respectively. The results showed that the model using PCA performs better. In the CNN part of the model, we have used the ResNet structure proposed by He et al. in 2015[1]. It can be seen in Figure 1 that the CNN (ResNet) part consists of several residual blocks. Each block contains a convolutional layer, batch normalization layer, activation function, and an additional convolutional layer to identity mapping the input data. The residual blocks, which add the link between the input and the output, can enhance the convergence and accuracy as well as ensure that the structure will not be overfitted easily.
In this work, several different sets of features (input variables) have been investigated. Firstly, the effect of different selection schemes of input variables on the accuracy of prediction results was investigated. It has been found that, compared with the traditional way of selecting the input variables, adding some ratios based on prior knowledge, e.g. as ) and others, as well as selected tray temperature leads to a much more accurate model. In addition, different sizes of the input “figures†for the ResNet part have been tested. Comparison experiments have been carried out based on the backpropagation (BP), PCA-BP, SOM-ResNet, and PCA-ResNet models. In addition, the minimum amount of data needed to support the different models have also also investigated.
Among the several models, the PCA-ResNet model has the best prediction accuracy and a smoother and more convergent error decline curve.
References
- He, K., et al., Deep Residual Learning for Image Recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016. p. 770-778.
- Ioffe, S. and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. in International conference on machine learning. 2015. PMLR.
- Krizhevsky, A., I. Sutskever, and G.E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks. Communications of the Acm, 2017. 60(6): p. 84-90.
- Simonyan, K. and A. Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition. Computer Science, 2014.
- Ochoa-Estopier, L.M., M. Jobson, and R. Smith, Operational optimization of crude oil distillation systems using artificial neural networks. Computers & Chemical Engineering, 2013. 59: p. 178-185.
- Shin, Y., R. Smith, and S. Hwang, Development of model predictive control system using an artificial neural network: A case study with a distillation column. Journal of Cleaner Production, 2020. 277: p. 124124.
- Rosli, M. and N. Aziz. Review of neural network modelling of cracking process. in IOP Conference Series: Materials Science and Engineering. 2016. IOP Publishing.
- Song, W., et al., Modeling the Hydrocracking Process with Deep Neural Networks. Industrial & Engineering Chemistry Research, 2020. 59(7): p. 3077-3090.